Getting Started
What is OpeNER?
OpeNER is a language analysis toolchain helping (academic) researchers and companies make sense out of “natural language analysis”. It consist of easy to install, improve and configure components to:
- Detect the language of a text
- Tokenize texts
- Determine polarisation of texts (sentiment analysis) and detect what topics are included in the text.
- Detect entities named in the texts and link them together. (e.g. President Obama or The Hilton Hotel)
The supported language set currently consists of: English, Spanish, Italian, German and Dutch.
Besides the individual components, guidelines exists on how to add languages and how to adjust components for specific situations and topics.
Quick Start Guide
Checkout the Quick start guide to get going right away.
OpeNER NLP Schema
In the following schema, there is the main schema of the work flow in OpeNER. This work flow could be seen as a processing chain for each language in OpeNER. The input regarding this schema is prepared to be raw text and the output of all the modules will be KAF.
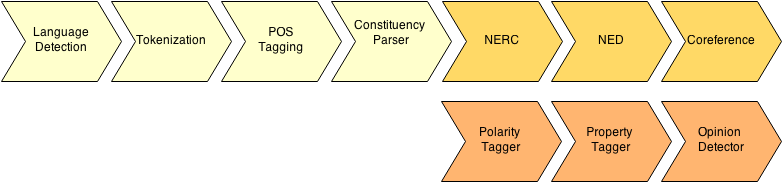
What technology is used?
The OpeNER toolchain consists of a broad mix of technologies glued together using Ruby. The prerequisits of running an OpeNER toolchain consists of:
- A mac / linux / unix kind of operating system
- Ruby 1.9.3+
- Python 2.7+
- Java 1.7+
- Perl 5+
You can find more information on how to get this all up and running at the Local Installations instructions page.
Don’t worry though. If you just want to jump in and get started, take a look at the freely available webservices.
Most of these requirements are already present on up-to-date unix like installations (including Mac OSX) or can be easily upgraded.
Every part of the OpeNER toolchain has individual dependencies. Most of which are included in the components themselves. Check out the individual manual pages of the components to for the specifics.
For example, checkout the usage and installation instructions of the Dutch Polarity tagger.
Main Functionality
Language Detection
This component is the responsible of detecting the language of an input document and delivers it to the correct language pipeline. If the language detector detects that a text is in English the input text should send the text flow to the English pipeline and so forth.
Technical characteristics
This language identification is based on the Mike Schilli’s perl Text::Language::Guess language guessing CPAN library. Its implementation is simple: Using Text::ExtractWords and Lingua::StopWords from CPAN, it determines how many of the known stopwords the document contains for each language supported are supported in Lingua::StopWords. The choose of this method is a choice between different existing components but prioritizing the response time.
An example of the expected input and output is as follows:
$ echo "this is an english text." | language-identifier
and the response is
<KAF xml:lang="en" version="2.1"> <raw>This is an english text.</raw> </KAF>
Check out the documentation of the language identifier or visit the webservices page
Tokenization
This component is the responsible of tokenizing the text in two levels, in sentence level and in word level. This component is crucial to the correct working of the rest of NLP components. This components is the first one of each language processing chain.
####Technical characteristics
This component uses Apache OpeNLP for all languages except French. The tokenizer contains two modules for sentence and token segmentation respectively. The components based on Apache OpeNLP are the same except for the models which depend on the languages and are trained according to the linguistic features of each language.
For the French, the component is based on a statistic method with a rules data file that helps the tokenization of tokens and sentences.
An example of the expected input and output is as follows:
$ echo "This is just an example, of how we tokenize. Bye, bye" | tokenizer -l en
and the response is
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<KAF xml:lang="fr" version="v1.opener">
<kafHeader>
<fileDesc />
<linguisticProcessors layer="text">
<lp name="openlp-fr-tok" version="1.0" timestamp="2013-06-14T10:41:08Z"/>
</linguisticProcessors>
</kafHeader>
<text>
<wf wid="w1" sent="1" para="1" offset="0">This</wf>
<wf wid="w2" sent="1" para="1" offset="5">is</wf>
<wf wid="w3" sent="1" para="1" offset="8">just</wf>
<wf wid="w4" sent="1" para="1" offset="13">an</wf>
<wf wid="w5" sent="1" para="1" offset="16">example</wf>
<wf wid="w6" sent="1" para="1" offset="23">,</wf>
<wf wid="w7" sent="1" para="1" offset="25">of</wf>
<wf wid="w8" sent="1" para="1" offset="28">how</wf>
<wf wid="w9" sent="1" para="1" offset="32">we</wf>
<wf wid="w10" sent="1" para="1" offset="35">tokenize</wf>
<wf wid="w11" sent="1" para="1" offset="43">.</wf>
<wf wid="w12" sent="2" para="1" offset="45">Bye</wf>
<wf wid="w13" sent="2" para="1" offset="48">,</wf>
<wf wid="w14" sent="2" para="1" offset="50">bye</wf>
</text>
</KAF>
Of course you can also use the language identifier instead of of the -l en
option. You can do this like this.
echo "This is just an example, of how we tokenize. Bye, bye" | language-identifier | tokenizer
The output will be identical.
Check out the documentation of the tokenizer or visit the webservices page
Part of Speech Tagging
This component is the responsible of assigning each token its morphological label. This component is crucial to the correct working of the rest of NLP components. This component also includes the lemmatization of the words.
Technical characteristics
This component is based on probabilistic POS tagging models trained with Apache OpeNLP library. The component is the same for all the languages in the consortium, the only differences are the models which depend on the languages (are trained according to the linguistic features of each language) and the lemmatizers. Lemmatization is dictionary-based. To perform English lemmatization the module uses three different methods for English and two for the rest of the languages:
- Plain text dictionary: “Word POStag lemma” dictionary in plain text.
- Using Morfologik-stemming: plain text dictionaries binarized as finite state automata using the morfologik-stemming project. This method requires less RAM with respect to the plain text dictionary.
- WordNet: only for English.
The part of speech tagger takes a KAF file as an input and will output KAF as well. You can take a look at the example kaf file here
An example of the expected input and output is as follows:
$ cat kaf-pos-tagger.kaf | pos-tagger
The response can be seen here.
Constituent parser
Parsing means providing the syntactic tree representation of a sentence. The component provides shift-reduced style constituent parsers for English, French, Italian and Spanish trained using the Apache OpenNLP API. For Dutch and German Alpino and Stanford parsers are required respectively. Constituent parsing is primarily used in OpeNER as an input to the Coreference resolution system.
Technical characteristics
The tree representation of the sentence organizes its branches in terms of phrases, namely, noun phrases, verbal phrases and so on. The leafs are the terminals of the sentence (the words themeselves) and the preterminals are the POS tags provided by a pos tagger model.
Most of the constituent parsers nowadays are statistical, e.g., probabilistic models are trained on a hand-annotated corpus. Such corpora are generally termed “treebanks”. In OpeNER the constituent parsers output two formats:
- KAF: a tree layer consisting of the terminals, the non-terminals and the edges between them.
- Penn Treebank: Bracketing format as defined by the Penn Treebank project.
For example, for the following sentence:
The dog ate the cat.
The OpeNER constituent parser could provide two outputs. In Penn Treebank format:
(S (NP (DET The) *(NN dog)) *(VP *(V ate) (NP ((DET the) *(NN cat)))) (.
.))
In a KAF constituent tree:
<constituency>
<tree>
<!-- Non-terminals -->
<nt id="nter0" label="ROOT"/>
<nt id="nter1" label="S"/>
<nt id="nter2" label="NP"/>
<nt id="nter3" label="VP"/>
<nt id="nter4" label="V"/>
<nt id="nter5" label="NP"/>
<nt id="nter6" label="DET"/>
<nt id="nter7" label="NN"/>
<nt id="nter8" label="DET"/>
<nt id="nter9" label="NN"/>
<nt id="nter10" label="."/>
<!-- Terminals -->
<!-- The -->
<t id="ter1"><span><target id="t1"/></span></t>
<!-- dog -->
<t id="ter2"><span><target id="t2"/></span></t>
<!-- ate -->
<t id="ter3"><span><target id="t3"/></span></t>
<!-- the -->
<t id="ter4"><span><target id="t4"/></span></t>
<!-- cat -->
<t id="ter5"><span><target id="t5"/></span></t>
<!-- . -->
<t id="ter6"><span><target id="t6"/></span></t>
<!-- tree edges. Note: order is important! -->
<edge id="tre1" from="nter1" to="nter0"/> <!-- ROOT <- S -->
<edge id="tre2" from="nter2" to="nter1"/> <!-- S <- NP -->
<edge id="tre3" from="nter6" to="nter2"/> <!-- NP <- DET -->
<edge id="tre4" from="ter1" to="nter6"/> <!-- DET <- The -->
<edge id="tre5" from="nter7" to="nter2" head="yes"/> <!-- NP <- NN (head) -->
<edge id="tre6" from="ter2" to="nter7"/> <!-- NN <- dog -->
<edge id="tre7" from="nter3" to="nter1" head="yes"/> <!-- S <- VP (head) -->
<edge id="tre8" from="nter4" to="nter3" head="yes"/> <!-- VP <- V (head) -->
<edge id="tre9" from="ter3" to="nter4"/> <!-- V <- ate -->
<edge id="tre10" from="nter5" to="nter3"/> <!-- VP <- NP -->
<edge id="tre11" from="nter8" to="nter5"/> <!-- NP <- DET -->
<edge id="tre12" from="ter4" to="nter8"/> <!-- DET <- the -->
<edge id="tre13" from="nter9" to="nter5" head="yes"/> <!-- NP <- NN (head) -->
<edge id="tre14" from="ter5" to="nter5"/> <!-- NN <- cat -->
<edge id="tre15" from="ter6" to="nter10"/> <!-- . <- . -->
<edge id="tre16" from="nter10" to="nter1"/> <!-- S <- . -->
</tree>
</constituency>
Named Entity Resolution
Named Entity Resolution consists of processing named entities in text. The overall objective is to be able to recognize, classify and link every mention of a specific named entity in a text. By Named Entity we usually mean a proper name of a person, a place, an organization, etc.
A named entity can be mentioned using a great variety of surface forms (Barack Obama, President Obama, Mr. Obama, B. Obama, etc.) and the same surface form can refer to a variety of named entities which make them ambiguous. For example, the form ‘san juan’ can be used to ambiguously refer to dozens of toponyms, persons, a saint, etc. (e.g, see http://en.wikipedia.org/wiki/San_Juan).
Furthermore, it is possible to refer to a named-entity by means of anaphoric pronouns and co-referent expressions such as ‘he’, ‘her’, ‘their’, ‘I’, ‘the 35 year old’, etc. Therefore, in order to provide an adequate an comprehensive account of named-entities entities in text it is needed to recognize the mention of a named-entity, to classify it as a type (e.g, person, location, etc.), to disambiguate it to a specific entity, and to resolve every form of mentioning or co-referring to the same entity in a text. In summary, to perform Named Entity Resolution. With the aim of making this problem more manageable, several Natural Language Processing tasks have been distinguished:
- Named Entity Recognition and Classification (NERC),
- Coreference resolution and
- Named Entity Disambiguation (NED).
Named Entity Recognition and Classification (NERC):
Generally, since MUC and CONLL (http://www.cnts.ua.ac.be/conll2003/ner/) shared tasks, NERC uses manually annotated data which serves to train machine learning models in a supervised manner. More recent trends aim at building automatic silver-standard and gold-standard datasets from existing large knowledge resources such as Wikipedia (Mika et al. 2008; Nothman et al. 2012) to avoid the reliance on hand-generated data for training.
NER taggers recognized a variety of Named Entity types, namely, references to PERSON, LOCATION, ORGANIZATION and MISCELLANEOUS, although in principle, given the appropriated annotated data, any type of Named Entity can be recognized. In this sense, OpeNER will, during its second year of development, be looking at recognizing and classifying Named Entity types releated with the Tourist domain such as restaurants, hotels, and perhaps monuments, theatres, etc.
The NERC components included in OpeNER for the first year take an input text (from KAF word forms) and recognizes and classifies Named Entities according to the 4 entity types of CoNLL, namely, location, organization, person and miscellaneous, creating new KAF element for each entity in this manner:
<entity eid="e9" type="organization">
<references>
<span>
<!--UN Office -->
<target id="t276" />
<target id="t277" />
</span>
</references>
</entity>
<entity eid="e13" type="location">
<references>
<!--Herat-->
<span>
<target id="t349" />
</span>
</references>
</entity>
Named Entity Disambiguation (NED):
Named Entity Recognition and Classification (NERC) deals with the detection and identification of specific entities in running text. Once the named entities are recognised they can be identified or disambiguated with respect to an existing catalogue. This is required because the “surface form” of a Named Entity can actually refer to several real things in the world. Wikipedia has become the de facto standard as such a named entity catalogue. Thus, if the form ‘San Juan’ appears in a given document, the NED task consist of deciding to which of the “San Juan” things listed in Wikipedia is actually the “San Juan” source form in that document referring to (e.g, see http://en.wikipedia.org/wiki/San_Juan).
In OpeNER the NED component is based on the DBpedia Spotlight (http://https://github.com/dbpedia-spotlight/dbpedia-spotlight/wiki) which uses the DBpedia (http://dbpedia.org) as the catalogue to perform the disambiguation. Within the OpeNER project new NED tools have been developed for each of the languages based on the English DBpedia Spotlight.
The NED component will take every entity recognized by the NERC component and try to decide to which actual thing is referring to. For example, it will take a entity such as
<entity eid="e13" type="location">
<references>
<!--Herat-->
<span>
<target id="t349" />
</span>
</references>
<externalReferences>
<externalRef resource="spotlight_v1" reference="http://dbpedia.org/resource/Herat_Province" />
</externalReferences>
</entity>
and produce a new external reference to (hopefully) point out to the actual thing in the DBpedia to which the “Herat” entity is actually referring to:
<entity eid="e13" type="location">
<references>
<!--Herat-->
<span>
<target id="t349" />
</span>
</references>
<externalReferences>
<externalRef resource="spotlight_v1" reference="http://dbpedia.org/resource/Herat_Province" />
</externalReferences>
</entity>
Coreference Resolution:
Coreference resolution aims at grouping together all the mentions in the text to a Named Entity. For example, a person can be referred to by using her proper name, Claudia Lawrence, or by other types of expressions, such as “her”, “she”, “the 35-year-old”, “Peter Lawrence’s daughter”, “the university chef”, etc. Coreference resolution will aim at linking together or “clustering” every mention to a given Named Entity. This is useful, for example, if we really want to know who is talking about what. In the Tourist Domain, it is hoped that the coreference resolution will help to clarify who says an opinion about which hotel, for example.
The Coreference component developed for OpeNER is an implementation of the Multi-Sieve Pass system for originally proposed by the Stanford NLP Group (Raghunathan et al., 2010; Lee et al., 2011) and (Lee et al., 2013). This system proposes a number of deterministic passes, ranging from high precision to higher recall, each dealing with a different manner in which coreference manifests itself in running text.
In order to facilitate the integration of the coreference system for the 6 languages of OpeNER we have included here 4 sieves: Exact String Matching, Precise Constructs, Strict Head Match and Pronoun Match (the sieve nomenclature follows Lee et al (2013)).
The coreference component requires two main requisites, external to the component itself, to work:
- A constituent parsing tree with head words marked. This is a syntactic tree with a mark for the head word for each of the nodes of the tree. This is done by the OpeNER constituent parser
- A number of dictionaries and static lists which provide genre, number and animacy information which is used to assign attributes to the mentions to be clustered. Which have been included in the OpeNER Co-reference component.
Constituent parser are usually probabilistic: they used hand-annotated built datasets (called treebanks) to train machine learning models in a supervised manner. The OpeNER pipeline provides such a constituent parser for each of the languages of the project.
The Coreference component reads text from KAF (including words, part of speech information, named entities recognized) and the syntactic tree and provides “clusters” or “groups” of mentions that the system guesses actually refer to a given entity. For example, take the following text:
"John is a musician. He played a new song. A girl was listening to the song. "It is my favorite," John said to her."
The OpeNER coreference component creates three clusters: the first groups the John-related mentions, the second one the “the song” mentions and the third one the “a girl” mentions.
<coreferences>
<coref coid="co1">
<!--John-->
<span>
<target id="t1"/>
</span>
<!--John-->
<span>
<target id="t27"/>
</span>
<!--a musician-->
<span>
<target id="t3"/>
<target id="t4"/>
</span>
<!--He-->
<span>
<target id="t6"/>
</span>
</coref>
<coref coid="co2">
<!--a new song-->
<span>
<target id="t8"/>
<target id="t9"/>
<target id="t10"/>
</span>
<!--the song-->
<span>
<target id="t17"/>
<target id="t18"/>
</span>
<!--It-->
<span>
<target id="t21"/>
</span>
<!--my favorite-->
<span>
<target id="t23"/>
<target id="t24"/>
</span>
</coref>
<coref coid="co3">
<!--A girl-->
<span>
<target id="t12"/>
<target id="t13"/>
</span>
<!--my-->
<span>
<target id="t23"/>
</span>
<!--her-->
<span>
<target id="t30"/>
</span>
</coref>
</coreferences>
The OpeNER coreference component is rule-based so this means that its adaptation for using it in the Tourist Domain will most likely consist of adding new specific sieves to that domain.
Polarity tagging
The polarity tagging is a task by means which terms in a text are tagged with their correct polarity and sentiment modifier label.
Words with polarity are words that express a negative or positive opinion, belief, attitude, etc. towards a certain topic. In our case polarity refers to out of context or “prior” polarity, i.e. to words which evoke something positive or negative independent from the context in which they are found. Polarity words can be nouns, verbs, adjectives and adverbs. The following examples contain negative polarity lemma’s like ruin, debt, problem and complaint and positive polarity lemma’s like pleasant, enjoy and delicious:
- Look, it seriously ruined our trip to Athens …
- In 2004 the president said that he felt that the debt was an enormous problem
- The stay was very pleasant and I have no complaint whatsoever
- We really enjoyed the delicious food
Sentiment modifiers are words that change or modify in certain way the polarity of a word or expression. We differenciate three subtypes of sentiment modifiers: intensifiers, weakeners and polarity shifters. Intensifiers (enormous, seriouly) and weakeners (relatively) are words that intensify or weaken the strength of an expression or polarity word. Polarity shifters (not, no, never) are negations which shift the polarity of an opinion word from positive to negative or vice versa. Here some examples are shown in italics: + In 2004 the president said that he felt that the debt was an enormous problem + Look, it seriously ruined our trip to Athens … + The standard room was relatively large + The hotel’s location was not a very interesting part of town + The stay was very pleasant and I have no complaint whatsoever + Will never return.
Opinion detection
The opinion detection is concerned with the identification of opinions in a text at the expression level. This task has received a lot of interesest in last period because of the explosion of the social networks. More and more companies use social networks to promote and offer their products, and they receive a lot of feedback from their customers as well. Considering the thousands of reactions that the people generates every on Social Networks, automatic analysis techniques become more and more interesting for extracting automatically opinions from this data.
In our case, we deal with fine-grained opinion extraction. This is not only about deciding if a text is in general expressing a positive or negative opinion, but detecting and extracting single opinions and the entities that build these opinions:
- Opinion expression: expressions that indicate emotions, sentiments, opinions or other private states
- Opinion holder: mentions of whom is the opinion from
- Opinion target: expressions that indicate what the opinion is about
For instance consider the sentence “I like the design of Ipod video”. These are the elements of the opinion extracted from it:
- Opinion expression: like
- Opinion holder: I
- Opinion target: the design of Ipod video
Where to go from here?
We prepared several example scenarios that explain how and for which applications you can use OpeNER technology. You can find them listed under the scenarios section on the left.
Besided the usage scenarios there are also a set of how-to guides available, check those out in the how to section.